Design Specification
The Design Specification form is where you define the details of your experiment. Some details are:
DOE Design Types
Using Adams Insight, you can import your own design matrix, or use a selection of built-in design types to help you create a design matrix. These options allow you the freedom to create the most effective experiment for your system.
When you use built-in designs, Adams Insight generates a design matrix according to specifications of the design type. Design types include:
Full Factorial
Full Factorial is the most comprehensive of the design types and uses all of the possible combinations of Levels for your factors. The total number of runs is mn, where m is the number of levels and n is the number of factors. Since the values for mn increase very quickly, Full Factorial is only practical for an experiment with few factors.
The Full Factorial algorithm can produce mixed-level designs that have a different number of values for each factor. Mixed-level designs can occur when you have discrete variables, which take on values from a fixed list. This contrasts with continuous variables, which take on arbitrary values that are usually constrained to a range. For example, a mixed-level design might have two Design Variables one with two levels and one with three levels. The number of runs for such a design is 2 * 3 = 6. In general, to compute the number of rows in a Full Factorial design, just multiply the number of levels of each design variable.
Fractional Factorial
Fractional Factorial and Plackett-Burman designs are referred to as reduced factorial designs. They are popular for screening important variables and are used principally with two-level factors. They enable you to estimate the effects on your system and, depending on the number of factors and the number of runs, estimate either none, some, or all of the two-factor interactions.
They are appropriate for two-level screening experiments when you are primarily interested in identifying the most significant factors (main effects) affecting the responses under investigation. As a subset of Full Factorial, these designs require fewer Trials, but may result in confounding of factor interactions with main effects. You should use these designs with the Screening method of experimental design, not RSM. Learn more about Screening and RSM.
These design types let you specify the number of trials in certain conditions. For example, for four factors and a linear model the only possible number of trials is 8. For five factors and a linear model one would have 8 or 16 trials.
The number of runs for a Fractional Factorial design must be a power of two (4, 8, 16...).
Plackett-Burman
Plackett-Burman designs are useful for screening a large number of factors to find the most important ones. These designs require the fewest runs of any classical design type, but do not allow you to estimate the interactions between factors.
The number of runs for a Plackett-Burman design must be a multiple of four (4, 8, 12, ..., 48).
Box-Behnken
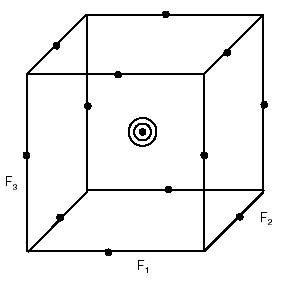
Box-Behnken designs use points on planes of the design space as shown in the diagram below. A Box-Behnken design requires relatively few trials. For example, a 12-factor design has 192 rows with 12 center points, for a total of 204 trials. Even though the number of trials is low, the results yield information on factor interaction, which makes these designs appropriate for RSM experiments in which the model type is quadratic. Box-Behnken designs require using each factor at three levels, and are available for designs with 3, 4, 5, 6, 7, 9, 10, 11, 12, or 16 factors.
Box-Behnken Design with Three Factors and Three Levels:
Central Composite Faced (CCF)
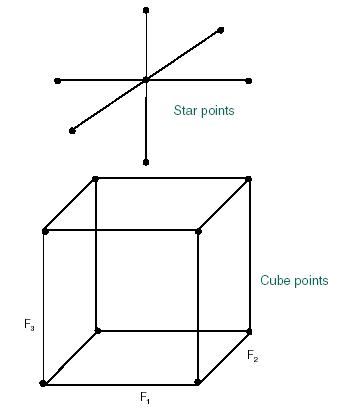
CCF designs use points on each factor axis (star points) in addition to points at the corners of the design space (cube points) and one or more center points, as shown in the diagram below. The CCF design produces a relatively greater number of runs than a Box-Behnken design, and is applicable to the same type of problems.
You can use CCF designs for RSM experiments in which the model type is quadratic. Standard CCF designs use the Fractional Factorial or Full Factorial design for a subset of factors in the experiment (in Adams Insight, the subset is always Full Factorial). For remaining factors outside of the subset, CCF designs use additional points that estimate quadratic effects. These designs allow high-quality prediction over the entire factor space.
CCF Design with Three Factors and Three Levels:
D-Optimal
The D-Optimal design produces a model that minimizes the uncertainty of coefficients. This design consists of a random collection of rows from a larger pool of Candidates that are selected using minimization criteria. D-Optimal designs let you specify the total number of runs in an experiment, supply existing rows from a previous experiment into a new experiment, and specify a different level for each factor. These features make D-Optimal designs the best choice in many situations, especially when experiment cost is a significant consideration.
D-Optimal designs extend to larger design matrices. For example, the more redundant the vectors (columns) of the design matrix, the closer to zero the determinant of the correlation matrix is for those vectors; the more independent the columns, the larger the determinant of that matrix is. Therefore, finding a design that maximizes the determinant D of this matrix means finding a design where the factor effects are maximally independent of each other.
Latin Hypercube
A Latin Hypercube design uses as many values as possible for each factor. Each factor's values are randomly ordered so that each run has a random combination of factor values.
Continuous factors have a different value for each run. The values are equally spaced, running from the minimum value to maximum factor value. Discrete factors have a fixed number of values. If there are more runs than discrete values, there will be runs with duplicate factor values. If there are fewer runs than discrete values, then not all values will be used.
The Latin Hypercube design is similar to a Sweep Study design, except that the factor values in each column are randomly ordered instead of uniformly sweeping from the minimum value to maximum value.
Investigation Strategies
The investigation strategies (methods) for creating a design matrix in Adams Insight include:
The first four strategies in the list reference attributes specified in the Settings tab of the Factor form. The two Variation methods reference attributes in the Variation tab of the Factor form.
Study - Perimeter
This method is used to evaluate the relative robustness of an analytical model. This method is often called Processes Health Check. The system under investigation is exercised at three different configurations:
■In the first trial, all the factors are set to their respective minimum values.
■In the second trial, the factors are set to their intermediate value.
■In the third trial, the factors are set to their respective maximum values.
When first investigating a system, it is good practice to determine the relative robustness of the nominal simulation. The first step in this process is to make sure that the nominal configuration runs well. The next step is to determine the likelihood that variants, of the nominal configuration, will run well. You can use the perimeter study to run three different configurations, which span the design space. The successful running of these three configurations will build confidence that you are working with a robust simulation. Before submitting a series of simulations which you may expect to run overnight, it is important to run a perimeter study to verify that the basic mechanics of building, running, and postprocessing the analytical system performs as expected.
If you choose the Perimeter Study as the Investigation Strategy, the model type will be automatically set to None and there will be no option for fitting the results or subsequently publishing or optimization. This Investigation Strategy is used to determine the relative robustness of the simulation and the simulation process.
Note: | If you select one factor for a Sweep or Perimeter Study, you can fit a model to the results. If you have more than one factor, you cannot fit a model, so the Model option in the Design Specifications form is set to None |
Study - Sweep
This method alters the respective inputs over a range. For example, let's say you wanted to alter the initial velocity of a vehicle from 50 to 100 KPH. You would define the initial velocity as a factor with settings 50 and 100. If this is the only factor in the investigation, you could select the sweep study investigation strategy in the Design Specifications form. The Number of Runs specifies how the factor interval will be divided. If you specified six trials, then the simulation would be run at 50, 60, 70, 80, 90, and 100 KPH. If only one factor is in the Factor Candidates List for a sweep study, then you can potentially fit the regression model. If more than one factor has been promoted than the Sweep Study permits, the None option for a regression model type and no subsequent model fitting or publishing of a fit model will be available. Sweep Studies are sometimes referred to as design studies.
DOE Screening (2 Level)
This method identifies the factors and combinations of factors that most affect the behavior of a system. You consider every factor that may potentially affect the response, and use a screening analysis to determine how much each contributes to the response.
A screening Design of Experiment (DOE) only picks high and low values of a setting range, and therefore is often called a two-level analysis. Screening helps narrow down experimentation to important factors and ensures that you do not omit significant factors or effects. Screening is usually followed by a more in-depth experiment, which is typically RSM, on the most important factors.
DOE Response Surface
This method fits polynomials to the results of the Trials in your experiment. The fitting functionality gives you an easy-to-use approximation of your system's behavior and performance. You can use this method for plotting and evaluating, for quick what-if studies, as input for an optimization algorithm, or as a subsystem model for a larger system.
RSM experiments require a greater number of runs than a screening experiment for the same number of factors. Therefore, it is advisable to first run a screening experiment, determine which factors are important, and then run an RSM experiment with this new subset of factors. Some common RSM designs are Box-Behnken, CCF, and D-Optimal.
Quadratic RSM provides three-level analysis because it uses high, low, and average values in the setting range. Cubic RSM uses high, low, 1/3, and 2/3 range values providing a four-level analysis.
Variation - Monte Carlo
This class of methods randomly sets values of the factors for each Trial. The goal of the investigation is to determine the effect of real-world variations upon the performance of the design. With a large number of trials, you can develop statistical predictions of design response.
The foundation of the method involves characterizing parameters with a Probability Density Function (PDF). This function must be specified for each parameter that will be varied in the analysis. Examples of parameters include spring stiffnesses, damping rates, and initial rotation rates.
Variation - Latin Hypercube
This investigation strategy is similar to the Variation - Monte Carlo strategy. The difference is in the sampling logic that generates the factor settings for each trial. The sampling logic for the Variation - Latin Hypercube method uses the modified Latin Hypercube algorithm.
Note: | This investigation strategy creates a collection of points, which approximates the specified distribution with fewer trials than the Variation - Monte Carlo method. |
Model
In performing a regression analysis, the objective is to fit an equation (referred to as the model) to the data such that the error between the values predicted by the equation and the actual observed values is minimized.
The model can have a constant term, linear terms, quadratic terms, and cubic terms. For example, if there are two factors, the forms are as shown below:
Type: | Form: |
|---|---|
Linear | R = a1 + a2*F1 + a3*F2 + e |
R = a1 + a2*F1 + a3*F2 + a4*F1*F2 + e | |
Quadratic | R = a1 + a2*F1 + a3*F2 + a4*F1*F2 + a5*F1^2 + a6*F2^2 + e |
Cubic | R = a1 + a2*F1 + a3*F2 + a4*F1*F2 + a5*F1^2 + a6*F2^2 + a7*F1*F2^2 + a8*F1^2*F2 + a9*F1^3 + a10*F2^3 + e |
where:
■F1: Value of the first factor.
■F2: Value of the second factor.
■a1-a10: Coefficients computed by the regression analysis.
■e: The remaining error, minimized by the regression analysis.
■R: Response value.